
Automation is the engine that powers effective cloud operations teams — but what does it really look like in practice?
Recently, we sat down with Sr. Solutions Architect and DevOps Engineer Phil Christensen to get an in-depth look at how to build a mature automation practice. We talked about the art and science of DevOps on AWS, including infrastructure as code development and the role of configuration management.
1. Why Automate?
The days when IT departments managed a monolithic, infrequently modified stack are long gone. And because the cloud frees us from the limitations of hardware, there are a lot more moving parts that we have to consider. There are no “completion dates” on a lot of cloud projects. Automation allows us to efficiently manage the fact that infrastructure changes all the time.
It used to be that scaling and movement meant throwing people and money at problems. You needed more hardware, or a bigger staff, and that meant more complex infrastructure buildout and development processes.
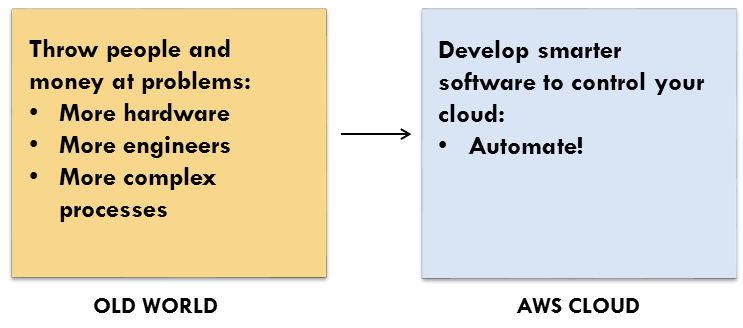
In the new world, we develop smarter software to control complex systems and deployments. In other words, we automate.
2. Principles of DevOps in the Cloud
We follow a few different principles for DevOps in the cloud:
- Design for constant change
- Build repeatable components, not snowflakes
- Anticipate failure
- Human effort = security risk
The first, and probably the most important, is to design for constant change. In modern development, the ground is constantly shifting underneath us, and we need to be comfortable with ongoing changes. That means building an environment that is not just suitable for Day 1, but can be managed efficiently and changed without too much risk.
Part of designing for constant change is not just at servicing an individual stakeholder’s concern, but do it in such a way that issues can be resolved more efficiently when they come up again. That means designing repeatable components, not doing ad hoc or one-off builds or deploys just to get the job done.
The third principle we follow is to anticipate failure. In the cloud, you must design a system that rarely fails, but you also need to design a system that fails well. We leverage some of the Auto Scaling features of AWS to make sure we have redundancy at every level of our stack.
And finally, human effort is a security risk. We try to avoid direct human intervention in an environment as much as possible and look for opportunities to avoid human error.
3. How do we design for constant change?
To design for constant change, first we need to understand what changes we anticipate. Here are the most common:
- New environment
- An update to infrastructure or OS configurations
- Instance failure or capacity limit
- Developers push code
When we are creating a new environment or a new network architecture in an environment, there are two clear approaches. We could build things manually (in the AWS console) or automate. The differences are clear:
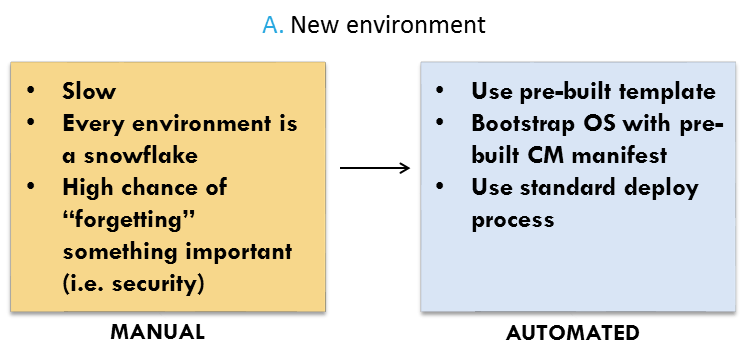
So every new environment follows the same build process, which begins with AWS CloudFormation templates:
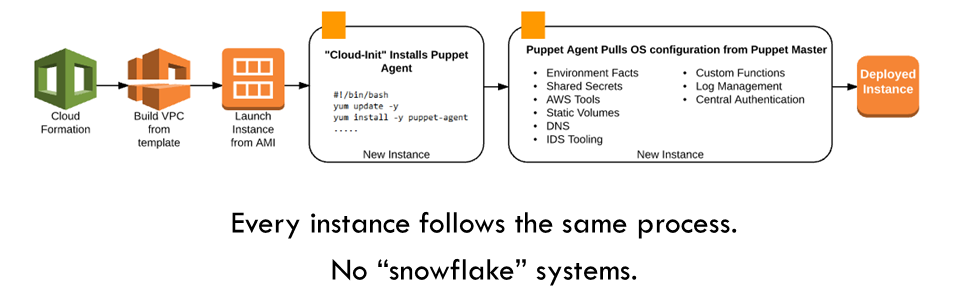
Why build a new environment this way rather than just in the AWS console? While it is true that this process is substantially slower the first time around, it lets you build out new environments consistently, while Puppet provides a “central source of truth” for the configuration of all your systems.
The value of Puppet (or the configuration management tool of your choice) is that when you want to change the OS, you can change code on the servers without making major changes to the servers themselves. That means changes can be rolled out to many instances at once — and be rolled back. When you are done, each server is in a known, ideal state. When you build and maintain your environment manually, change is risky and slow:
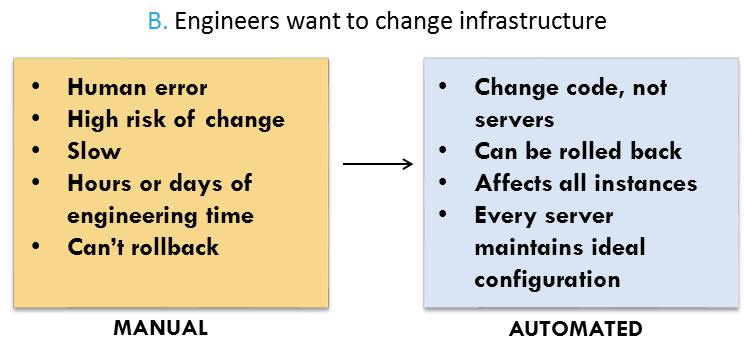
As part of all of our automation, we use Git and other source control utilities so that whenever we create a set of changes, we have a clear audit log.
To get the full details on what we do for C. Instance failure or D. Deployment, watch the webinar.
4. Disposable Infrastructure
This leads us into what is becoming increasingly a very prominent concept within the infrastructure automation world, and that is the idea of disposable infrastructure. The core concept of disposable infrastructure is that it is expensive, time-consuming, and often boring to fix a server — so why fix a server when you can throw it away and build a new one?
Of course, in order to reach this state, full automation of the instance boot process is necessary (as in the process described above). But the benefits of this system are tremendous — we talk about this in depth in this blog post.
5. The Security Impact of Automation
Sometimes when people think of automation, they assume it automatically increases their risk. But in fact, we find that automation greatly reduces the risk of potential security flaws.
This is due to the fact that we have a controlled, standardized build and update process. We can build and update a system with little to no direct intervention in an environment, which of course reduces the chance of human error. If we need to push out an emergency patch to our environment, our preexisting Puppet architecture lets us do this in a very standardized way. We can update a central script and make sure this is pushed out to all environments, and if for some reason an environment gets launched with an old configuration, it is automatically changed when it checks into Puppet.
Most of the things that we take care of are either in AWS CloudFormation or Puppet. Here is an oversimplified list of security automation aspects:
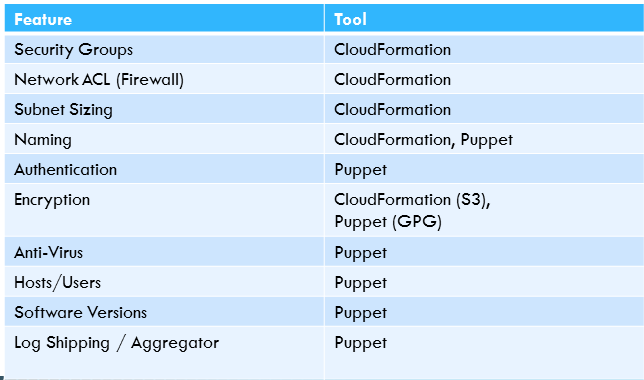
Finally, a step that Logicworks takes very seriously is proactive scanning of the environments that we deploy. This is a little more complicated because it leverages a Central Automation Plant that has the knowledge and access rights to iterate through all of our client environments looking for particular flaws, mistakes, or common errors. Essentially, it allows us to find the “error” in the haystack; with thousands of security groups, finding one with a misconfigured security group that has, say, Port 22 open is almost impossible. These scanners can either alert our NOC or actively configure the security group to close the port. Of course, in order for these tools to work properly in the first place, you need to have a standard build process.
These technical components are the foundation of a cloud DevOps practice, but it is your engineers’ belief in the value of this system and dedication to continuous improvement that will determine its success. In many ways, this is what your engineers have always dreamed of: greater control over the production state of systems, greater control over who can make what changes to the environment, and an end to constant firefighting. In some cases, it is the IT managers and executives that need to keep up.
Logicworks is an enterprise cloud automation and managed services provider with 23 years of experience transforming enterprise IT. Contact us to learn more about our managed cloud solutions.